代码如山重构是削,架构似水适配求轻。昔日石山累卵,今朝注水得清。
本文回顾了个人博客从 v1 到 v2 的重构:由 Java + Next.js + 多数据库 的臃肿堆栈,转向 Go (Fiber) + SvelteKit + PostgreSQL 的极简组合,内存占用腰斩,运维降至 3 个容器。核心提出 “注水静态架构” (Rehydrated Static Architecture)——将 SSR 渲染时机从“用户请求时”提前到“数据变更时”,以静态 HTML 为默认分发,再通过 WebSocket 注入实时互动;独创 load() 驱动 ISR 依赖收集,让 Go 根据声明精准重新生成页面,配合 原子写入 与 svmarkdown 组件化渲染 等一系列细节,实现静态性能与动态交互的优雅平衡。最终收敛出一句发问:“这个博客,真的需要这个吗?”——复杂度为内容让路,方是工程本质。
一年了,该更新一下新的了... 这个用了挺多 AI ,因为时间紧任务重,一个人实在忙不过来了,唉,最近在 Review,AI 的代码安全性真是不敢苟同。。。。。。
写下这篇文章的时候,grtblog-v2 的核心功能开发已经基本告一段落。 https://github.com/grtsinry43/grtblog-v2
目前正在进行稳定性测试,确认稳定后会逐步修复 Bug、补充功能,并拉朋友内测。当前的测试地址在:
https://blog-next.grtsinry43.com/ https://blog-next.grtsinry43.com/
(注意仅供测试,数据与本站不会同步)
本站已更新,稳定后再发布新版项目~
感谢 @starnighter@blogv2.starnighter.com 同学帮助测试还有 PR ,帮助我完成了一些功能开发~
为什么要重写
这个博客最初只是我学习 React SSR 时的练手项目。一年多过去,它承载了我大量的技术实验——每次有新东西想试,就往里堆。学到了很多,但代价是:它变成了一座精致的屎山。
作为部署在 1C2G / 2C4G 小鸡上的个人博客,v1 实在太重了。每次部署要拉起 MySQL、MongoDB、Redis、MeiliSearch 等一堆服务,JVM 和 Next.js 联手吃掉几乎所有内存。更让人疲惫的是 Next.js 的黑盒实现和不断暴露的安全问题——维护它本身就需要一套沉重的心智模型。
新时代的 PHP:RSC 的边界错位与工程代价
首先是对比下
咱们首先对比一下,狠狠抨击自己之前的石山,然后讲一下我这次换成了什么:
| 问题 | 具体表现 |
|---|---|
| 架构复杂 | Java 后端 + Next.js 前端 + Umi.js 后台 + Python 推荐服务,四个独立技术栈 |
| 数据库过多 | MySQL + MongoDB + Redis + Elasticsearch + MeiliSearch,五个模块各司其职但运维成本极高 |
| 部署门槛高 | Docker Compose 需要 6+ 个容器,配置繁琐,甚至阻碍了作者自己后续维护 |
| 仓库膨胀 | Git 历史混入大量二进制资源,仓库体积快速膨胀 |
| 边界模糊 | 设计系统、内容模型与插件机制(PF4J)的职责逐渐交叉 |
| BFF 废弃 | 规划的 BFF 层未能落地,停留在空目录 |
| 决策 | v1 做法 | v2 做法 | 理由 |
|---|---|---|---|
| 后端语言 | Java (Spring Boot) | Go (Fiber) | 编译为单二进制,内存占用从数百 MB 降至数十 MB |
| 前端框架 | Next.js (React) | SvelteKit (Svelte 5) | 更小的 bundle、更少的运行时开销、Runes 语法更直觉 |
| 管理后台 | Umi.js (React) | Vue 3 (Naive UI) | 轻量且与前台技术栈解耦,并基于 lithe-admin 二开 |
| 数据库 | MySQL + MongoDB | PostgreSQL 一个搞定 | JSONB 覆盖文档型需求,减少运维复杂度 |
| 搜索 | Elasticsearch + MeiliSearch | 后端内建 | 博客体量下内建搜索足够,去掉两个重型依赖 |
| 推荐系统 | 独立 Python 微服务 | Go 内建 | 减少跨语言通信和部署复杂度 |
| 静态生成 | Next.js ISR (框架内建) | 自研 ISR (Go 驱动) | Go 后端直接调度渲染、原子写入,完全可控 |
| 实时通信 | Socket.io + Netty | 原生 WebSocket | 去掉 Socket.io 协议层开销 |
| 部署 | 6+ 容器 | 3 容器 (Go + SvelteKit + Nginx + DB) | 大幅降低部署门槛 |
注水静态架构 (Rehydrated Static Architecture)
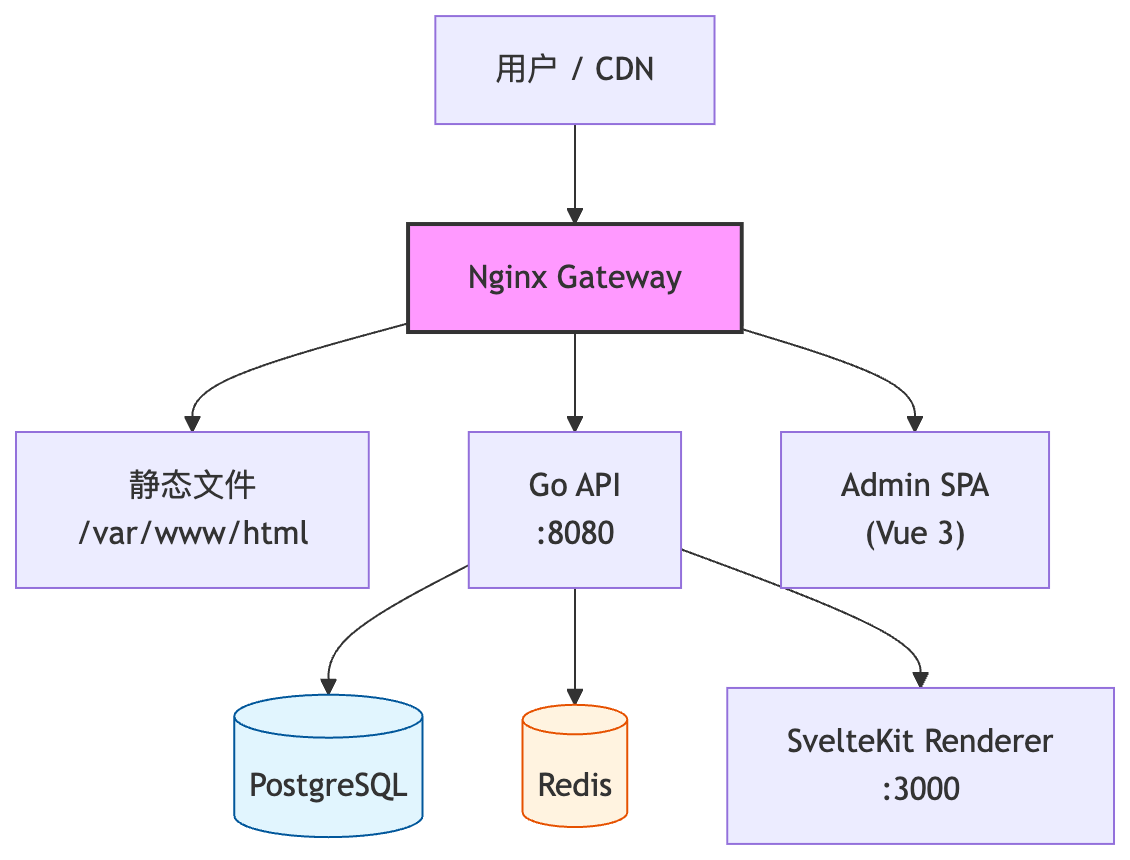
这是 v2 的核心设计理念,一句话概括:
将 SSR 的渲染时机从「用户请求时」提前到「数据变更时」,将渲染产物以纯静态文件的形式交给 Nginx 分发,同时通过 WebSocket 为在线用户注入实时更新。
它试图在静态站点的极致性能和动态应用的实时交互之间找到一个平衡点。拆开来看,分为三层:
- 静态先行 (Static First) — 所有公开页面默认为纯静态 HTML,由 Nginx 直接分发,首屏速度拉满,CPU 占用趋近于零。
- 增量生成 (Incremental Generation) — 仅在内容变更时,由 Go 控制平面驱动 SvelteKit 渲染器生成受影响的页面,不做全量重建。
- 实时注水 (Realtime Rehydration) — 客户端通过 WebSocket 接收评论、点赞及内容的热更新,在线用户无需刷新即可看到最新状态。
换一个更本质的角度来理解:
SSR / SSG / ISR 这些词只是在描述"渲染发生在哪里"。真正决定架构设计的,是 数据与页面的依赖关系,以及 渲染产物如何存储和复用。
它的效果是:
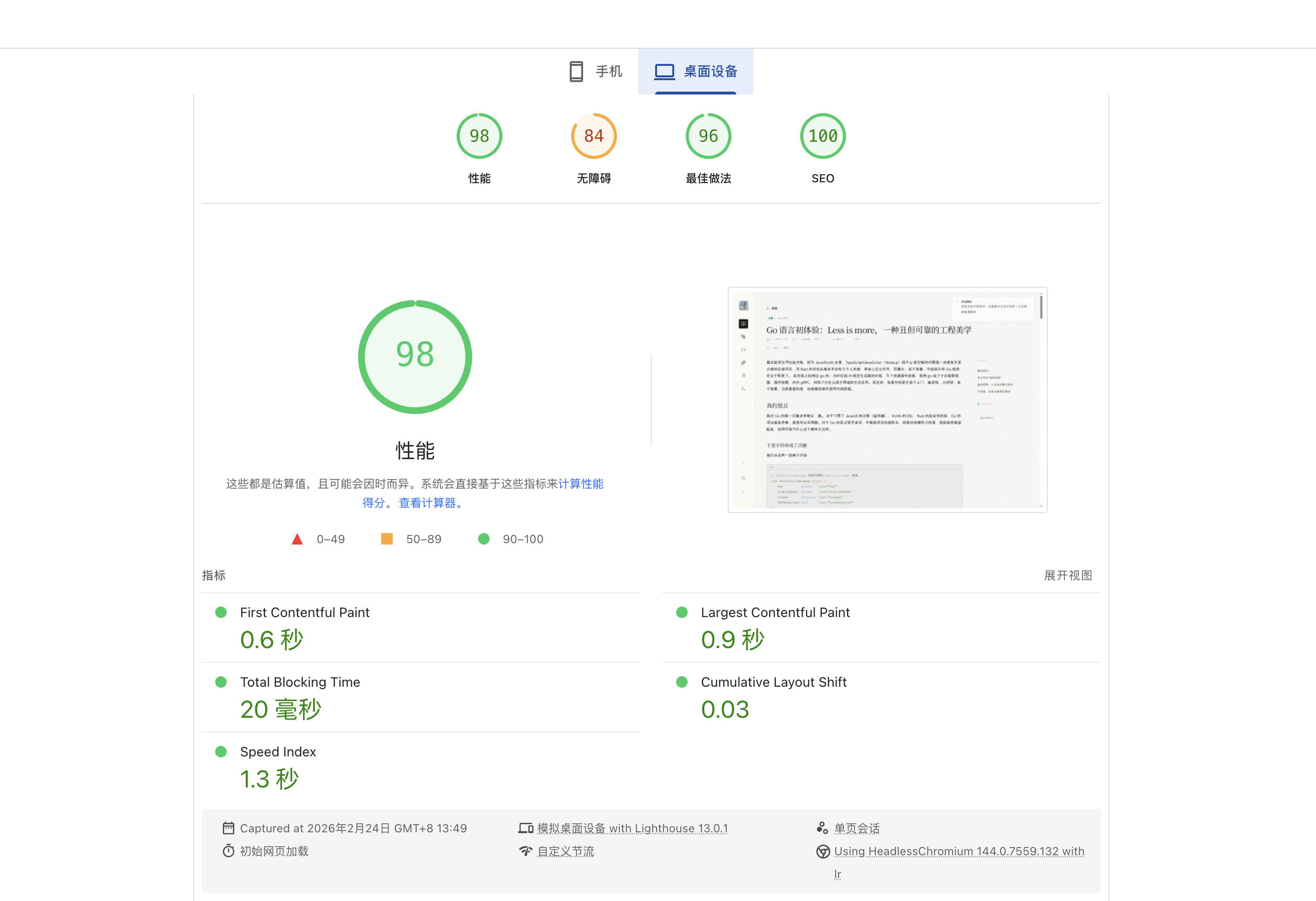
发生了什么
我们可以用一个图来看出核心的更新机制是什么的。
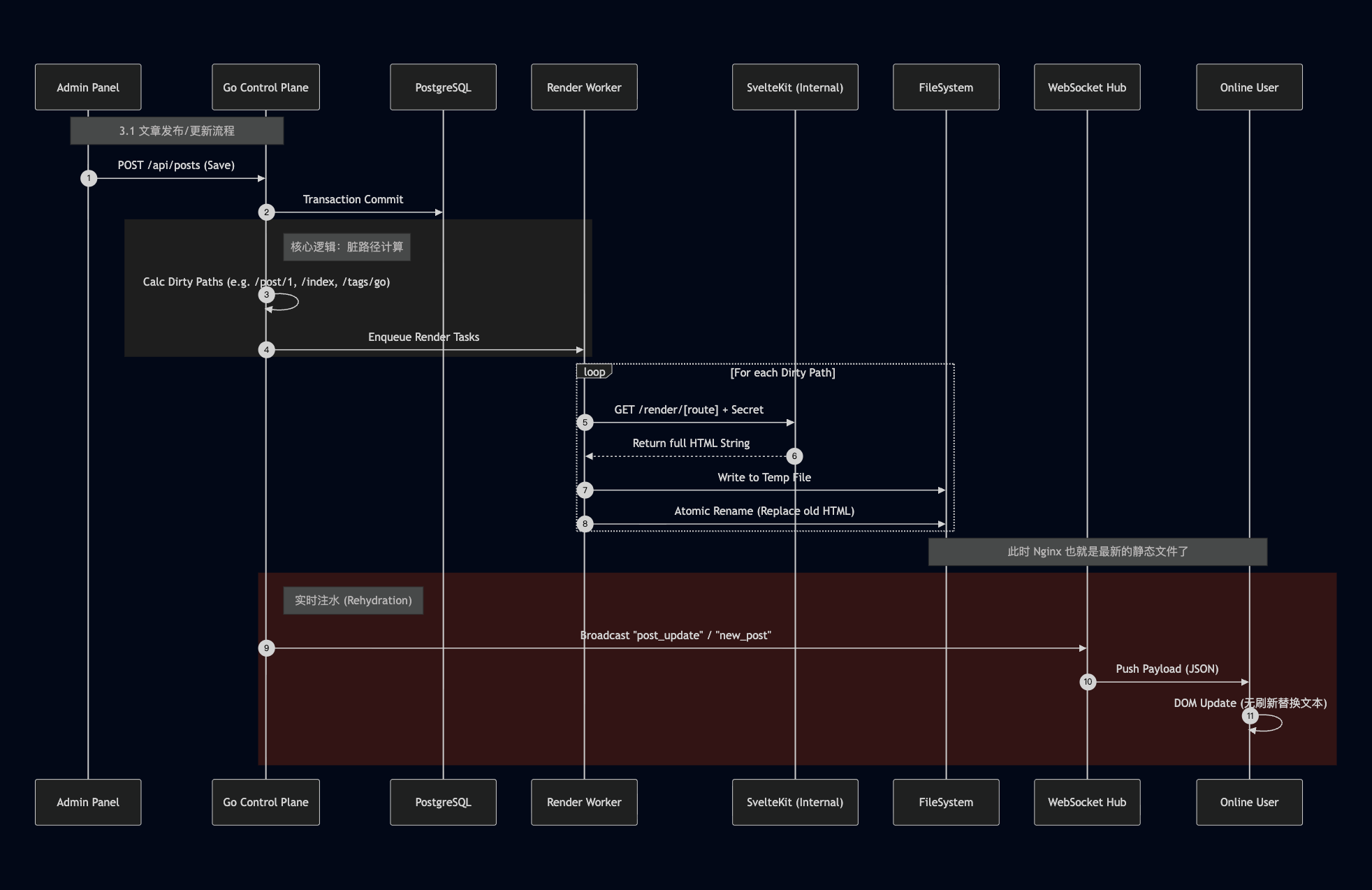
ISR 工作流
ISR(Incremental Static Regeneration)是本项目的核心机制,类似 Next.js 的 ISR,但完全白盒,可以完全掌控:
Admin 发布文章
│
▼
Go 写入数据库
│
▼
DirtyPathCalculator 计算受影响路径
例: /posts/new, /index, /tags/Go, /feed.xml
│
▼
RenderQueue 异步任务入队
│
▼
Worker 请求 SvelteKit Renderer
GET http://renderer:3000/posts/new
│
▼
AtomicWriter 原子写入静态文件
TempFile -> Rename (防并发读写白屏)
│
▼
WebSocket Hub 广播 post_created 事件
│
▼
在线用户收到实时通知
实时更新流
Admin 修改文章错别字
│
▼
Go 更新 DB + 广播 WS post_update (带 payload)
│
▼
在线阅读用户的 Svelte Store 收到 payload
│
▼
无感替换 DOM 文本节点(无需刷新)
│
▼
Go 异步触发静态文件重新生成(为后来者服务)
说说实现细节
从 MPA 到 SPA:静态文件如何水合
这种架构面临的第一个问题是:如果页面变成了静态文件,客户端怎么水合成 SPA? 好在 SvelteKit 的框架魔法大多发生在SSR的时候。在 SvelteKit 中,页面加载分为两种路径:
- 首次访问 (SSR):服务端执行
load(),拼接完整的 HTML 返回给浏览器。 - 客户端路由跳转 (CSR / SPA):当你点击链接从
/跳转到/posts/1时,SvelteKit 不会请求新的 HTML。它的客户端 Router 会去请求一个特殊路径:/posts/1/__data.json,拿到 JSON 后在前端完成数据替换和 DOM 更新。
因此,我们只需在每次渲染时同时缓存 HTML 和 __data.json,就做到了一个"静态的单页应用"——首次访问命中静态 HTML,水合之后的导航跳转走 __data.json,行为完全等同于 SPA。
load() 驱动的 ISR 依赖收集
传统的 ISR 是框架内闭环的,但 v2 的后端是 Go,前端是 SvelteKit。Go 怎么知道文章 A 更新了,首页也要跟着重新渲染?我们就需要一个依赖标记的机制。
1. 页面在 load 阶段显式声明依赖
SvelteKit 的数据获取,精髓在于这个load()函数,由于我们整个页面都是在这里获取初始数据,所以我们不妨在拿数据的时候打个 Tag(web/src/routes/posts/[slug]/+page.server.ts):
const post = await getPostDetail(fetch, params.slug);
trackISRDeps(event, `post:detail:${post.id}`);
首页等复杂页面也会收集一堆 Tag:
trackISRDeps(
event, 'home:recent-posts', 'home:recent-moments',
'home:activity-pulse', 'home:inspiration-stats'
);
2. Header 与反向索引
在 web/src/hooks.server.ts 中,我拦截了响应,把收集到的 Tag 塞进 HTTP Header:
event.locals.isrDeps = new Set<string>();
const response = await resolve(event);
headers.set('x-grt-deps', JSON.stringify(Array.from(event.locals.isrDeps)));
Go 向 Renderer 发起内网抓取时(server/internal/app/htmlsnapshot/service.go),解析这个 Header,并将关系写入自己的 Redis 映射表:
isr:url:<url> -> depsisr:dep:<dep> -> urls
3. 事件驱动失效
当我在后台修改了文章,Go 的事件总线触发 ISR(server/internal/app/isr/subscriber.go):
deps := []string{
"home:recent-posts",
fmt.Sprintf("post:detail:%d", articleID),
}
urls := []string{"/", "/posts", "/posts/page/1"}
return service.Invalidate(ctx, deps, urls)
Go 拿着 deps 去反向索引中查出所有受影响的 URL,去重后压入 Redis Sorted Set 队列。
至此,一条完整的链路成型:前端声明依赖 → 后端解析并建立索引 → 数据变更时精准触发重渲染。
异步客户端组件与请求
如果全站静态化,点赞数、评论区怎么动态加载? 对于点赞和观看量这种轻交互,我们可以 mounted 之后请求和修改,而评论这种重交互,则可以使用 <QueryRoot> 组件(web/src/lib/ui/common/QueryRoot.svelte),这下就有了个低配的 Suspense(bushi
onMount(async () => {
const [{ QueryClientProvider }, { getOrCreateQueryClient }] = await Promise.all([
import('@tanstack/svelte-query'),
import('$lib/shared/clients/query-client')
]);
client = await getOrCreateQueryClient(options);
Provider = QueryClientProvider;
if (loader) {
const loaded = await loader();
Loaded = loaded.default;
}
ready = true;
});
这样,第一屏不会引入太重的请求部分,而客户端组件加载完成之后由 TanStack Query 管理,最大化管理了请求数据。
svatoms:舒服的树形数据传递
在由各种“交互岛屿”构成的页面中,Prop drilling(属性逐层透传)是维护的地狱。结合 Svelte 5 的 Runes 特性,我封装了 svatoms 来实现数据树与组件树的解耦。
https://github.com/grtsinry43/svatoms https://github.com/grtsinry43/svatoms 
1. Context 挂载模型数据
在页面顶层(web/src/routes/posts/[slug]/+page.svelte),把 load 来的数据挂载到专属的 Context 中。使用 getter 保证 SvelteKit 导航后的数据自动同步:
postDetailCtx.mountModelData(() => data.post ?? null);
const { updateModelData } = postDetailCtx.useModelActions();
2. 细粒度切片订阅
子组件只订阅自己关心的切片(PostDetailMain.svelte):
const aiSummaryStore = postDetailCtx.selectModelData((data) => data?.aiSummary ?? '');
const tocStore = postDetailCtx.selectModelData((data) => data?.toc ?? [], { equals: sameToc });
这里的 equals可以在返回复杂对象时,手动等价比较避免了无意义的重渲染。
3. 跨树联动,比如阅读进度同步
比如DetailMarkdownContent.svelte 在正文滚动时,更新 detailPanelCtx 里的 activeAnchor。远在另一棵 DOM 树分支上的 MobileNavBar.svelte 订阅同一个 Context 并高亮当前目录。 生产者和消费者无需在同一条 props 链上,状态流转的心智模型很舒服。
渲染平面的优雅降级:静态优先 + 原子写入
之前说过,由于静态的特性,哪怕 Go 后端和 SvelteKit 全部宕机,博客依然要能抗住流量。
1. Nginx 静态
在 deploy/nginx/nginx.conf 中,静态文件是一等公民:
location / {
# 命中静态文件直接返回,未命中才回源到 SSR
try_files $uri $uri.html $uri/index.html @frontend_fallback;
}
location @frontend_fallback {
proxy_pass http://renderer_ssr;
}
2. 原子操作避免损坏
高并发下,如果 Go 正在把渲染好的 HTML 写入磁盘,用户恰好访问,就会看到残缺的白屏。 在 server/internal/app/htmlsnapshot/service.go 中,这里利用Rename操作的原子性:
tmp, _ := os.CreateTemp(dir, ".snapshot-*.tmp")
tmp.Write(body)
tmp.Close()
os.Rename(tmpName, filePath)
并且,如果访问 Renderer 遇到 404,Go 会主动清理旧的静态文件,避免出现“后台删了,前台还在”的幽灵页面。
Markdown渲染
在个人博客的开发中,大多数人会选择引入 markdown-it 或 marked,直接转成 HTML 字符串,然后用 {@html content}(或 v-html / dangerouslySetInnerHTML)一把梭。 ……但这样做意味着完全脱离了框架的组件生命周期——Svelte 不知道那段 HTML 里有什么,自然也无法管理它。 为了在运行时安全、优雅地将 Svelte 组件嵌入到 Markdown 正文中,同时保留AST解析能力,我抽离并开源了svmarkdown。
https://github.com/grtsinry43/svmarkdown https://github.com/grtsinry43/svmarkdown
这个库是基于Makrdown-it的强大能力的
Phase 1: 解析层 (Parser Layer) —— 构建干净的 AST
在 src/parser.ts 中,利用 markdown-it 对原始文本进行词法分析,拿到扁平的 Token 流,然后通过一个游标解析器,将这些 Token 转换成一颗干净的、高度结构化的自定义抽象语法树(AST),即 SvmdNode。
在 src/types.ts 中,可以看到 AST 节点被严格定义为几种:
SvmdTextNode:纯文本节点。SvmdElementNode:标准 HTML 标签(如p,strong,a)。SvmdCodeNode:代码块节点(携带语言类型和源码)。SvmdComponentNode:自定义组件节点。
通过引入 markdown-it-container 插件,svmarkdown 会拦截所有类似 :::callout 或 :::gallery 的自定义块。在解析阶段,它会将冒号后面的标识符和属性提取出来,直接组装成一个 SvmdComponentNode,放入 AST 树中。
Phase 2: 渲染层 (Render Layer) —— Svelte 原生递归组件
拿到 AST 后,就进入了 Svelte 渲染阶段。
在 src/Markdown.svelte 和 src/internal/RenderNode.svelte 里,利用 Svelte 的 <svelte:element> 和 <svelte:component> 实现了 AST 的递归遍历。
在 <RenderNode> 这个内部核心组件里,会进行分发(Dispatch):
- 如果是普通元素:直接渲染
<svelte:element this={node.tag}>。 - 如果是代码块:将代码字符串作为 props 传入用户定义的外部 CodeBlock 组件。
- 如果是自定义组件:系统会去查找顶层传入的
componentMap。
{#if node.type === 'component'}
{@const MappedComponent = componentMap[node.name] || FallbackComponent}
<svelte:component this={MappedComponent} {...node.props}>
<SvmdChildren nodes={node.children} />
</svelte:component>
{/if}
用这个库,心智负担也很低:
const componentBlocks = Object.fromEntries(
componentDefinitions.map((component) => [component.name, true])
) satisfies SvmdParseOptions['componentBlocks'];
export const markdownComponents: SvmdComponentMap = {
h1: MarkdownHeading,
h2: MarkdownHeading,
h3: MarkdownHeading,
h4: MarkdownHeading,
h5: MarkdownHeading,
h6: MarkdownHeading,
p: MarkdownParagraph,
ul: MarkdownList,
ol: MarkdownList,
li: MarkdownListItem,
blockquote: MarkdownBlockquote,
hr: MarkdownHr,
table: MarkdownTable,
thead: MarkdownThead,
tbody: MarkdownTbody,
tr: MarkdownTr,
th: MarkdownTh,
td: MarkdownTd,
a: MarkdownLink,
img: MarkdownImage,
code: MarkdownCodeBlock,
gallery: MarkdownFallback,
callout: MarkdownFallback,
timeline: MarkdownFallback,
'year-card': YearCard,
'link-card': LinkCard,
'footnote-link-card': FootnoteLinkCard
};
export const markdownParseOptions: SvmdParseOptions = {
componentBlocks,
markdownItPlugins: [],
markdownItOptions: {
html: true,
linkify: true,
typographer: true
}
};
export const markdownRenderOptions: SvmdRenderOptions = {
allowDangerousHtml: true
};
轻量、极速、一切皆组件,这样或许还挺优雅的。
写在最后
回头看,v1 的问题不是任何单一技术选型的失败,而是复杂度在无人察觉中的缓慢堆积——每多一个中间件都"有道理",每多一层抽象都"有必要",直到整个系统的重量超过了它所承载的内容本身。
v2 的核心收获不是选了更好的框架,而是学会了在每个岔路口问自己一句:这个博客,真的需要这个吗? 内存占用腰斩不止,维护的心智模型也清爽了许多。更重要的是,我终于能把精力从"和基础设施搏斗"转回到"做有趣的产品"上了。
grtblog-v2 还需要完整的测试和问题修复,但距离稳定应该不会太远了。如果你也在做类似的全栈博客、ISR 优化,或者对 Svelte 5 + Go 的组合感兴趣,欢迎 Star 仓库 、提 Issue,或者直接在评论区聊聊你的想法。
感谢读完这篇有点长的技术复盘。