事情起源于课内的课程实验作业…因为要求要用爬虫,不必说课内讲的一言难尽,更不必说就算讲了我也会在课上自己写项目不听这个,不过作为目前炒作很火的一样工具,其在获取数据层面提供的便利还是不能忽视的,于是我还是打算浅浅研究了一下,应付完了作业,然而还要水实验报告,于是就有了这篇文章,比较基础,不过用在日常一些小小的需求上还是够的。
[!WARNING] 看前提示 未经授权的网页爬取是非法的,可能违反网站的服务条款。 请确保在进行爬取之前已获得网站的许可。 本文的所有教程仅供学习使用,切记不可影响网站的正常运行
文本的教程就以初学者都喜欢的爬取豆瓣电影 top250 信息为例。
准备工具
首先这里用到的库就是 requests 和 BeautifulSoup,pip 安装一下即可
pip install requests beautifulsoup4
提示用 Arch Nix 等发行版的同学,py313 版本我还没试过,不知道能不能装,总之现在主线版本问题有点多,可以用 conda 什么先过渡一下,等主流生态跟进再说
from json import JSONDecoder
import requests
import json
import io
import re
from bs4 import BeautifulSoup
这里因为我还需要按照要求保存到文件…我就存到 json 了,这些不必多说
用户代理和 cookie
这个,大部分的站点肯定会有反爬措施的,毕竟内容网站随便开放爬虫活不了多久,可能会有 UA 正则,ip 封禁,登录校验等等。
对于 UA(用户代理),我们直接取自我们自己的浏览器就好,打开网页,按下键盘上的 F12 打开开发者工具,找到“网络”选项卡,单击任意请求,在请求头中就可以获得 User-Agent 的字段,
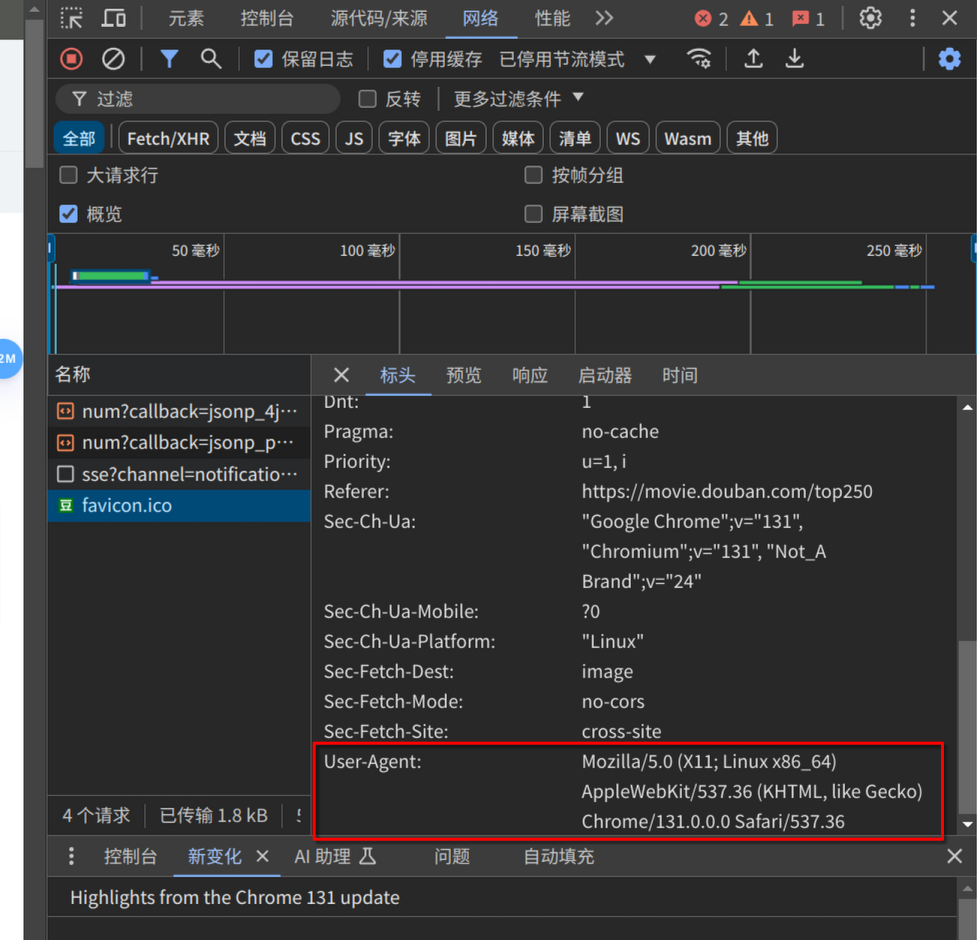
比如我的 UA 信息如下:
user-agent:
Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36
对于 ip 和登录,豆瓣默认是对于异常请求的 ip 进行限制,要求登录后访问,我们这里就直接拿下登录信息,解决这两个限制,还是像上文一样,在请求中找到 Cookie 字段。
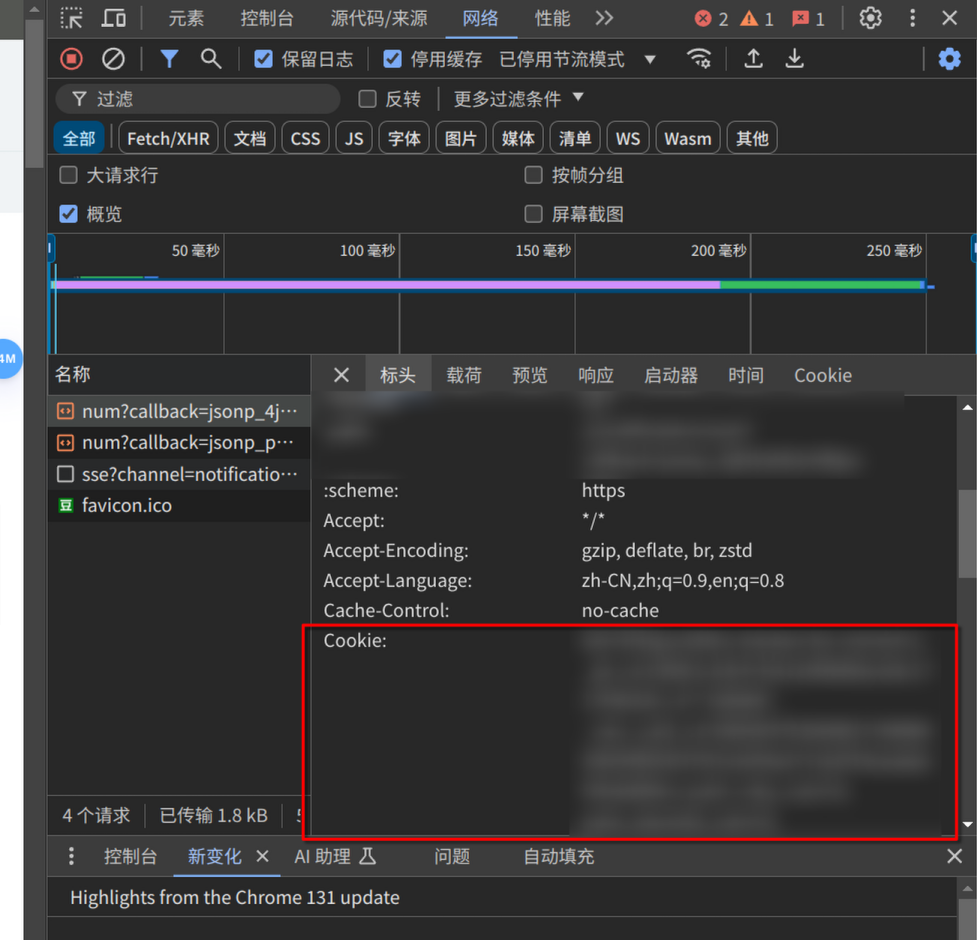
你可以将其粘贴并保存在同目录下的 cookie.txt 文件中,于是我们便可以请求网页的信息
def get_data(url):
ua = '***your_ua***'
headers = {
'User-Agent': ua,
'Cookie': io.open('cookie.txt', 'r', encoding='utf-8').read()
}
response = requests.get(url, headers=headers)
return response.text
解析网页与提取信息
早些时间,我曾用 js 弄过类似的爬虫,感觉那种类似 CSS 选择器的语法很舒服,而 BeautifulSoup 使用的也是类似的逻辑,于是便非常好上手。
在解析内容的函数中,我们先初始化 parser 实例
def parse_data(html):
soup = BeautifulSoup(html, 'html.parser')
接下来我们便可以像 CSS 选择器一样获取网页的元素 .select(),比如我们想要拿到单个影片信息卡片,便可以找到 ol(类名 grid_view) > li > div(类名 item)
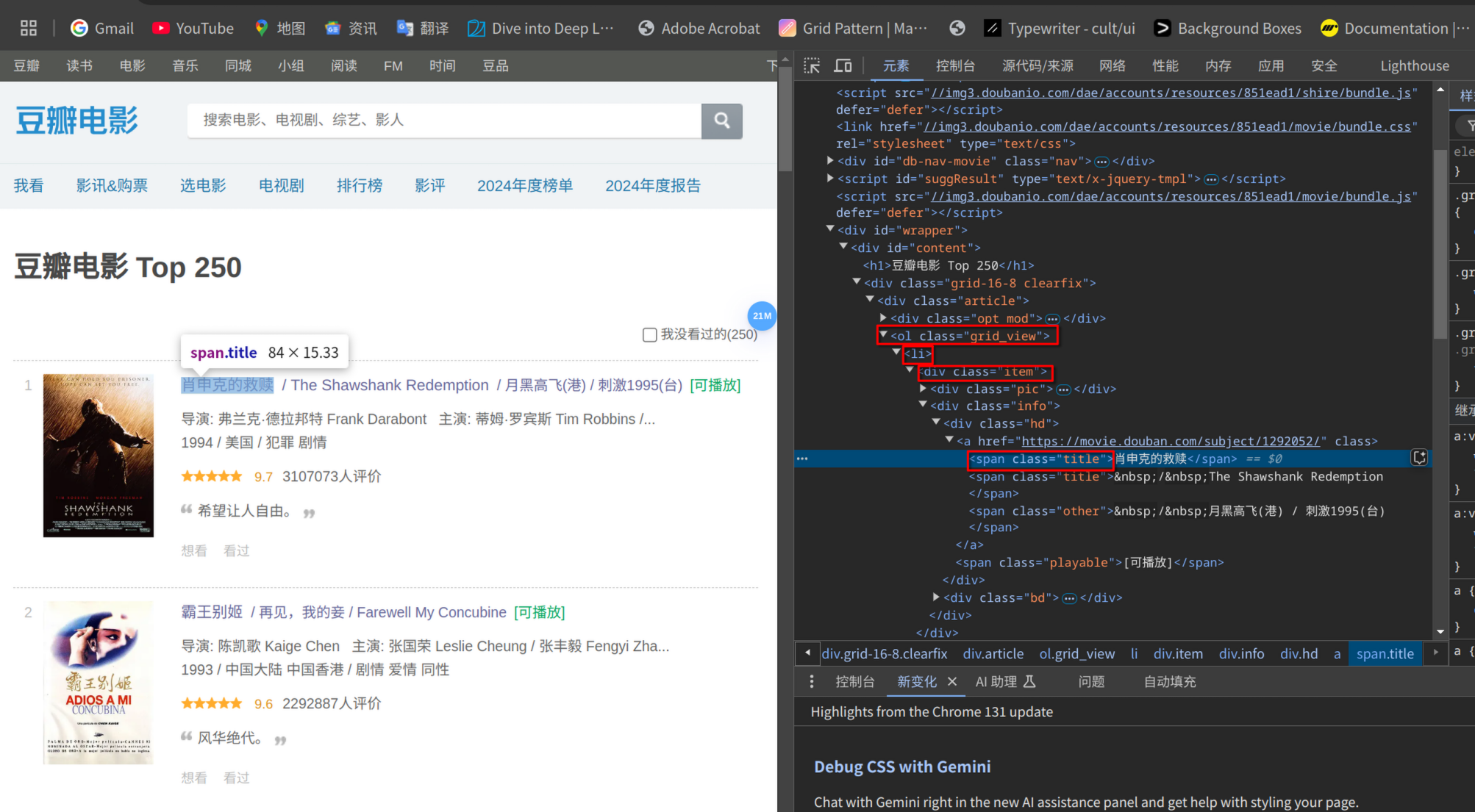
.select_one() 拿到 span 元素之后,我们可以使用 .get_text() 方法得到其 innerText(strip=True 用于删去空格)
对于 <a> 标签等,其所需值在属性上的,使用 .attrs.get() 即可拿到属性
for item in soup.select('ol.grid_view li div.item'):
name = re.sub(r'\s', '', item.select_one('span.title').get_text(strip=True).split('/')[0])
print("name:", name)
# 取出英文名,从所有名字中找出名字均为英文或空格匹配等等,没有则为空
en_name = ''
all_name = item.select('span.title')
all_name.append(item.select_one('span.other'))
for i in all_name:
if re.match(r'^[a-zA-Z\s]*$', i.get_text(strip=True)[3:]):
en_name = i.get_text(strip=True)[2:]
item_link = re.sub(r'\s', '', item.select_one('div.hd a').attrs.get("href"))
img_src = item.select_one('div.pic img')['src']
info = item.select_one('div.bd p').get_text(strip=True)
comment = item.select_one('span.inq').get_text(strip=True) if item.select_one('span.inq') else ''
对于复杂的 css 选择器也是支持的,比如说:
intro = soup.select_one('div#link-report-intra').get_text(strip = True)
directors = [a.get_text(strip=True) for a in soup.select('div#info span: nth-child(1) span.attrs a')]
actors = [a.get_text(strip=True) for a in soup.select('div#info span: nth-child(3) span.attrs a')]
types = [a.get_text(strip=True) for a in soup.select('div#info span [property = "v: genre"]')]
小技巧
对于有一些内容,或许可以手动先找到其 api 的地址,豆瓣这个额还是很好找的,毕竟发现还在用 jsonp 这种上古神器。
我们这里还是在浏览器控制台,发现其完整评论的显示接口地址是 /j/review/full
于是我们便可以直接调用接口爽快获取()
short_comment = JSONDecoder().decode(get_data(short_comment_link.replace("/review", "/j/review") + "full"))['html']
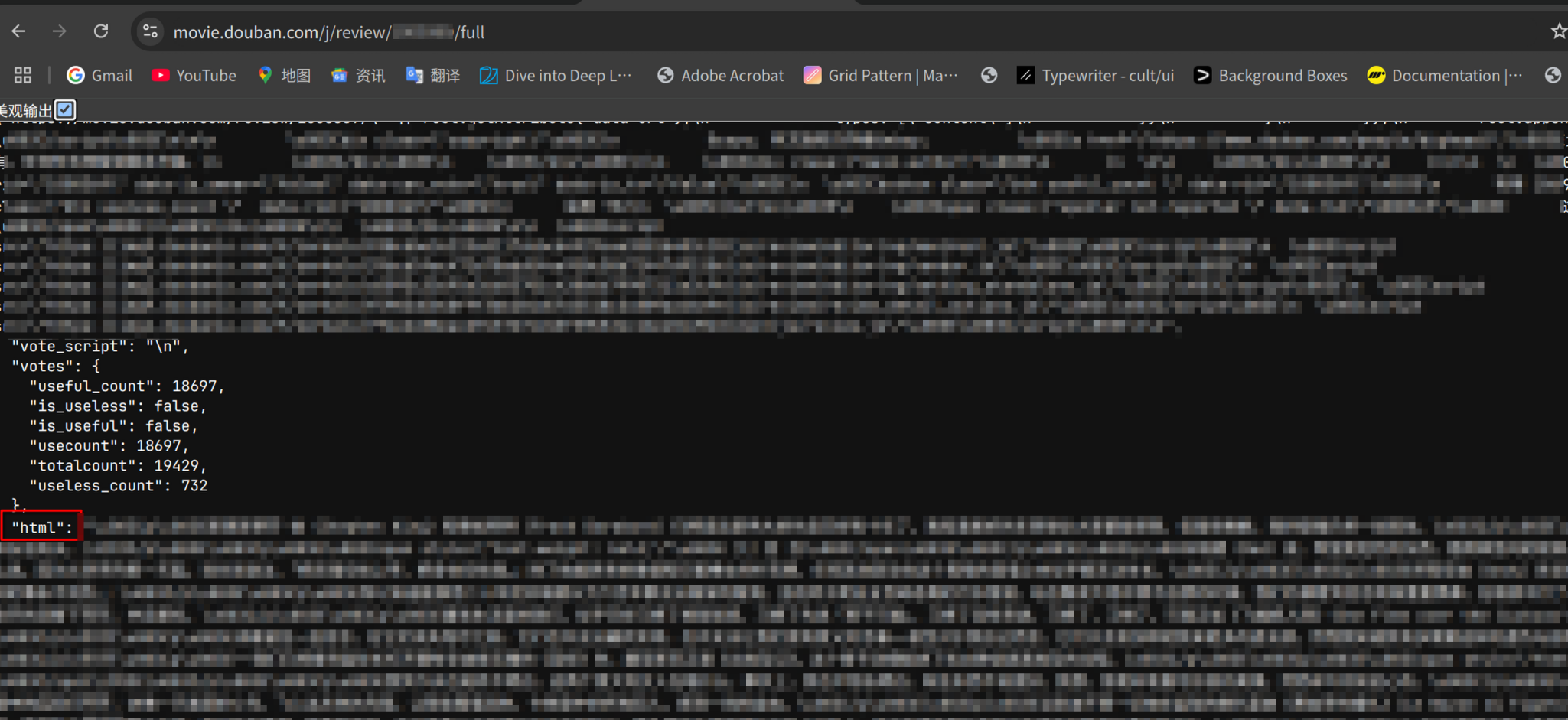
我们观察一下就可以发现其 html 字段,这里可以再解析一下,拿到文本,就可以收工啦
def save_data(data):
with io.open('result.json', 'w', encoding='utf-8') as f:
f.write(json.dumps(data, ensure_ascii=False))
总结
就一个小爬虫,爬爬数据,没什么技术含量,主要也就是为了应付课内看了一下。
唯一就是爬的时候可以多换 ip,看看 f12 请求,可以 curl 慢慢尝试,拿到需要的字段,有些地方可以逃课(比如 api)可以适量观察一下