云起一纸微言,雾散千行码迹;借问技艺何往,原是匠心独运。
文章以「Agent Skills」为轴,拆解了一种渐进披露的轻量规范:将指令打包为带 YAML frontmatter 的 Markdown 目录,通过索引层(名称、描述、触发条件)实现路由,只在触发时展开正文,避免上下文膨胀与注意力涣散。目录形如 SKILL.md + scripts/references/assets,支持 context(inline/ fork)、paths 条件可见、上下文压缩摘要保留等语义。作者手搓 mini-runtime,涵盖 frontmatter 解析 → 注册索引(字符预算截断)→ 按需加载与变量替换 → 压缩保留头部。分析指出,Skill 并非重引擎,而是一份约定,本质是 “先路由再加载” 的注意力分配设计;截断保留头部因 skill 呈倒金字塔结构;字符预算比条目数更具跨模型普适性。末尾抛出 “自愿蒸馏” 的冷思:规范化的 skill 可能成为厂商训练数据与锁定用户的杠杆,但书写本身倒逼认知明晰,得失自衡。
这篇想聊的是 Skills——但不是再写一篇"Skills 是什么、怎么配置"的入门贴,那种文章已经有不少了。我想做的是反过来:从一个怀疑者的角度去拆它。最早看到 Skills 的时候我的第一反应是"动态加载提示词,包装一下而已",但真的去读规范、读 Claude Code 泄露出来的实现、自己手搓一个最小运行时之后,有些东西开始变得有意思——它确实不只是 prompt 工程的换皮,但也没有官方博客说得那么"革命性"...
手搓系列 02。
说来惭愧,01 和 02 之间隔了多久呢?久到海枯石烂…
倒不是没动力——01 写完的第二天我就受伤了。属于是身体抢在我之前完成了"用力过猛"的演出,接下来就是几个月的躺平(物理)。 期间手动实现过微前端框架,写过简单的打包工具,但是一直没有发,感觉自己的理解还是不够,一拖就拖到了 AI 时代,这次也算是小小的蹭蹭热度,搞搞 skills。
真难绷。一篇博客的更新节奏,中途隔绝了天堑。
回到正题。
最早听说 Skills 的时候,我的想法是"就这?炒冷饭而已"。
动态加载提示词,找个文件写一堆 instruction,感觉不如直接塞进 。但是实际测试中,不写进 CLAUDE.md 省事CLAUDE.md / AGENTS.md,信息容易滑出上下文,compact 之后就失效;写太多,塞进去的内容一直占着上下文的位置,token 消耗巨大。
于是 Skills 这么诞生了,算是一种新的协议规范。
先看概念吧
Anthropic 的工程博客《Equipping agents for the real world with Agent Skills》(2025-10-16)把 Skill 定义为:
Organized folders of instructions, scripts, and resources that agents can discover and load dynamically to perform better at specific tasks.
Building a skill for an agent is like putting together an onboarding guide for a new hire.
我们可以圈几个关键词:folders(不是单个文件)、dynamically(不是预加载)、onboarding guide(不是 prompt 工程)。
Skills 的目录长什么样
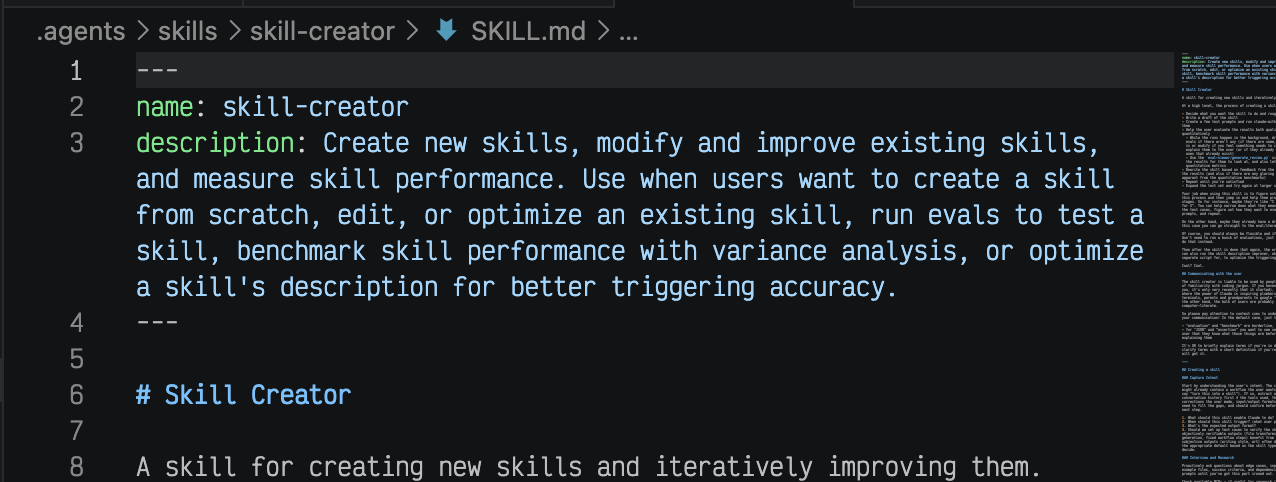
最简形态是一个目录,里面放一个 SKILL.md,开头是 YAML frontmatter,正文是 markdown。frontmatter 的必需字段只有两个:name 和 description。
更复杂一些的 skill 可以有 scripts/、references/、assets/ 等子目录,正文里通过文件名引用。
my-skill/
├── SKILL.md # 必需
├── scripts/ # 可选:可执行代码
├── references/ # 可选:参考文档
└── assets/ # 可选:模板/字体/图标
本质:Markdown + frontmatter 的结构化封装
看刚才的目录就明白,Skill 本质上就是一个 .md 文件,开头用 YAML frontmatter 定义元数据,正文是带结构的 prompt 模板。
frontmatter 里能写的东西还挺多的(后文会展开讲):
name:技能叫什么description:干什么的when_to_use:什么时候该调用arguments:接受哪些参数allowedTools:执行时能用哪些工具
所以 Skills 感觉更多是定义了一个规范。谁可以用、什么时候用、接受什么参数、输出什么格式,定义清楚了 AI 才能稳定执行。听起来像废话,但是这样写感觉效果确实好一些。
Skills 的优势架构
所以他相比提示词功能好在哪里呢?
Skill 系统最核心的设计是把 Skill 的信息分成两层。
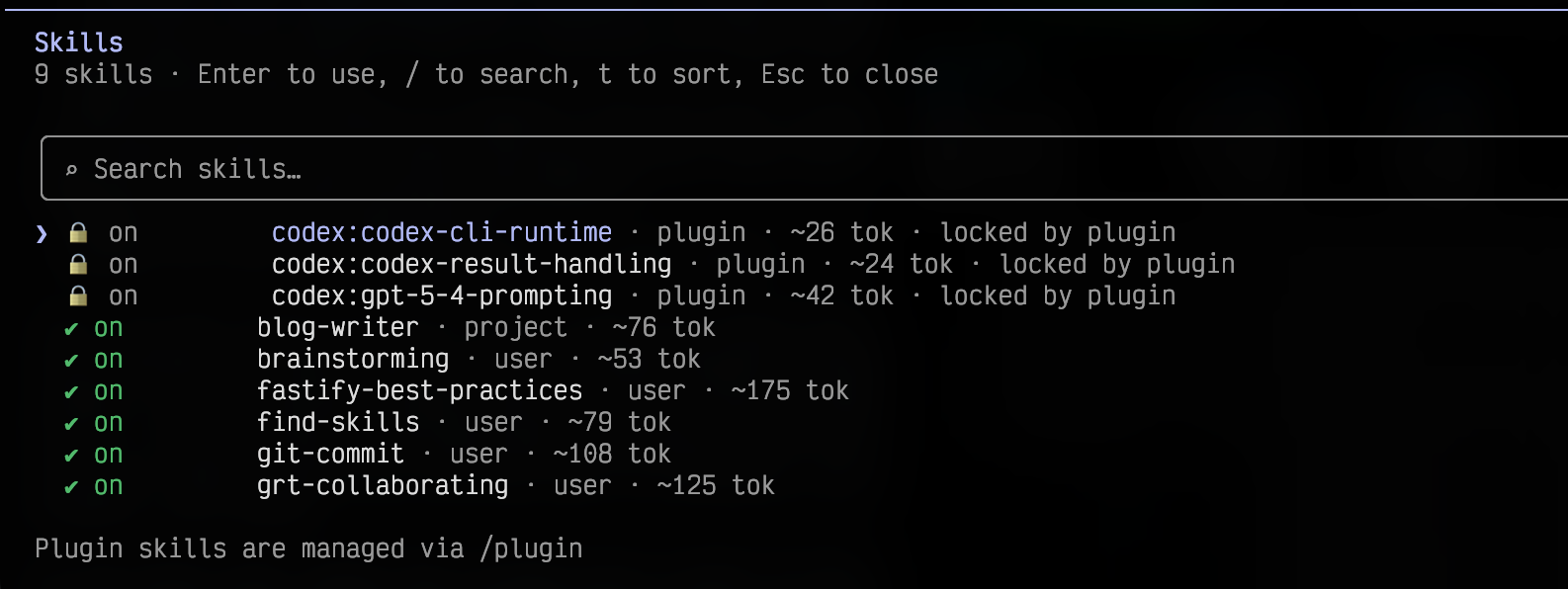
第一层是索引层:Skill 的 name、description、when_to_use。这部分在 AI 启动时就会注入上下文,AI 靠这个来做路由决策——(Claude 偷偷想)“用户这句话好像匹配 brainstorming,我应该调用它”。
第二层是正文层:Skill 文件里的完整 prompt 内容。这部分只有在 Skill 被真正调用时才会展开注入对话,不会一开始就塞进上下文,这样说不了几句就压缩了。
这样做的好处是上下文经济学的微妙平衡:AI 不需要一开始就读完所有 Skill 的全部内容,只需要知道"有哪些技能、干什么的",等真正要用了再加载正文。全塞进去的话,token 消耗巨大不说,AI 还容易在各种 Skill 的风格里左右摇摆 ,像个选择困难症患者。
这个「先路由、再加载」的设计,可能就是设计所在了。
像一本组织良好的手册——目录在最前面,章节在中间,详细附录在最后,Claude 按需翻页。
然后 Anthropic 还说:
Agents with a filesystem and code execution tools don’t need to read the entirety of a skill into their context window when working on a particular task. This means that the amount of context that can be bundled into a skill is effectively unbounded.
换句话说,只要 agent 有文件系统和代码执行工具,bundle 的内容就可以"实质上无限大"。Skill 不依赖任何特殊运行时,它只假设 agent 有 bash 和文件系统,由此他就能无缝迁移到别的 Agent 实现。
Skills 的调用机制
谈到这里,Skills 是怎么被使用的呢? Skills 有两条触发路径,用户和模型都可以调用,但最后执行的流程都是大同小异的。
用户入口:
比如用户在对话框输入 /blog-writer,Agent 框架判断这是一个 prompt 类型的命令,生成完整的 skill 原文。skill 内容作为一条隐藏的用户消息注入当前对话,emm 至少形态上和普通对话绘画里的用户消息一样。同时,skill 声明的 hooks 会被注册,已调用的 skill 会被记录。
模型入口:
模型启动时只能看到一份「技能索引」,就像你点菜时候看到的菜单一样:每个 skill 的 name、description、when_to_use,来自 SkillTool 的 prompt 和 skill_listing attachment。模型靠这份索引做路由决策——“用户这句话好像匹配 git-commit,我应该调用 SkillTool”。
fork 的情况:
当然,有一个特殊情况,就是 Agent 是会使用小弟的,也就是 subagent 如果 skill 的 frontmatter 里声明了 context: fork,skill 的内容会被送往一个子 agent 独立执行。
Skills 的核心语义(也就是之前的字段)
然后前段时间 cc 的代码不是不小心开源了么,于是我们来看看 Anthropic 是怎么设计 Skills 的。
接下来说的是 Anthropic 的实现,因为我们想学习他们的设计,Skills 的通用字段其实很少
context:inline 与 fork
frontmatter 里的 context 字段决定 skill 被调用后如何执行。
inline 是默认行为:skill 内容注入当前对话,AI 在当前上下文中继续工作。适合需要借助当前对话历史才能完成的技能,得知道用户之前聊了什么。(这里默认就是这样,同一个上下文)
fork 则是把 skill 内容发给一个子 agent 独立执行,完毕后再把结果汇回来。适合需要屏蔽当前上下文干扰的技能——比如你让 AI 写代码,但它总想顺便帮你修 bug。
paths:条件可见,而不是条件执行
skill 的 frontmatter 里可以声明 paths,指定绑定到哪些文件路径。
也就是指定哪些 skills 可见:当 AI 操作的文件路径匹配了 skill 的 paths 声明,这个 skill 才进入可用技能列表;路径不匹配,这个 skill 对 AI 来说就不存在。 大仓库里不需要一次性暴露所有 skill,skill 和对应部分相关,AI 进入那片区域时对应的 skill 才出现。
比如你有一个 css-naming skill,专门检查命名规范,就可以用 paths: ["**/*.css", "**/*.scss"] 绑定到样式文件。只有当 AI 在处理样式文件时,这个 skill 才会出现——平时它就像不存在一样。
上下文压缩摘要保留
对话历史变长时,AI 会做上下文压缩。skill 内容是作为用户消息注入的,会随对话历史自然在上下文空间向后移动。 但是这里 Anthropic 开了个后门,压缩时系统不会把 skill 内容彻底删掉,而是摘要后作为 attachment 继续保留——记录 name、path 和内容摘要。所以压缩后 AI 仍然知道这个 skill 被调用过,继续遵守它的指引。
但是 fork 出来的 skill,子 agent 结束后会主动清理 skill 内容,毕竟用完就扔掉了。(过河拆桥说是)
allowedTools、hooks、变量替换
allowedTools:skill 可以声明执行时能用哪些工具,调用时会临时放开权限边界。
hooks:调用 skill 时可以规范下 agent 的行为,比如"执行前先做 X"、“执行完后做 Y”。
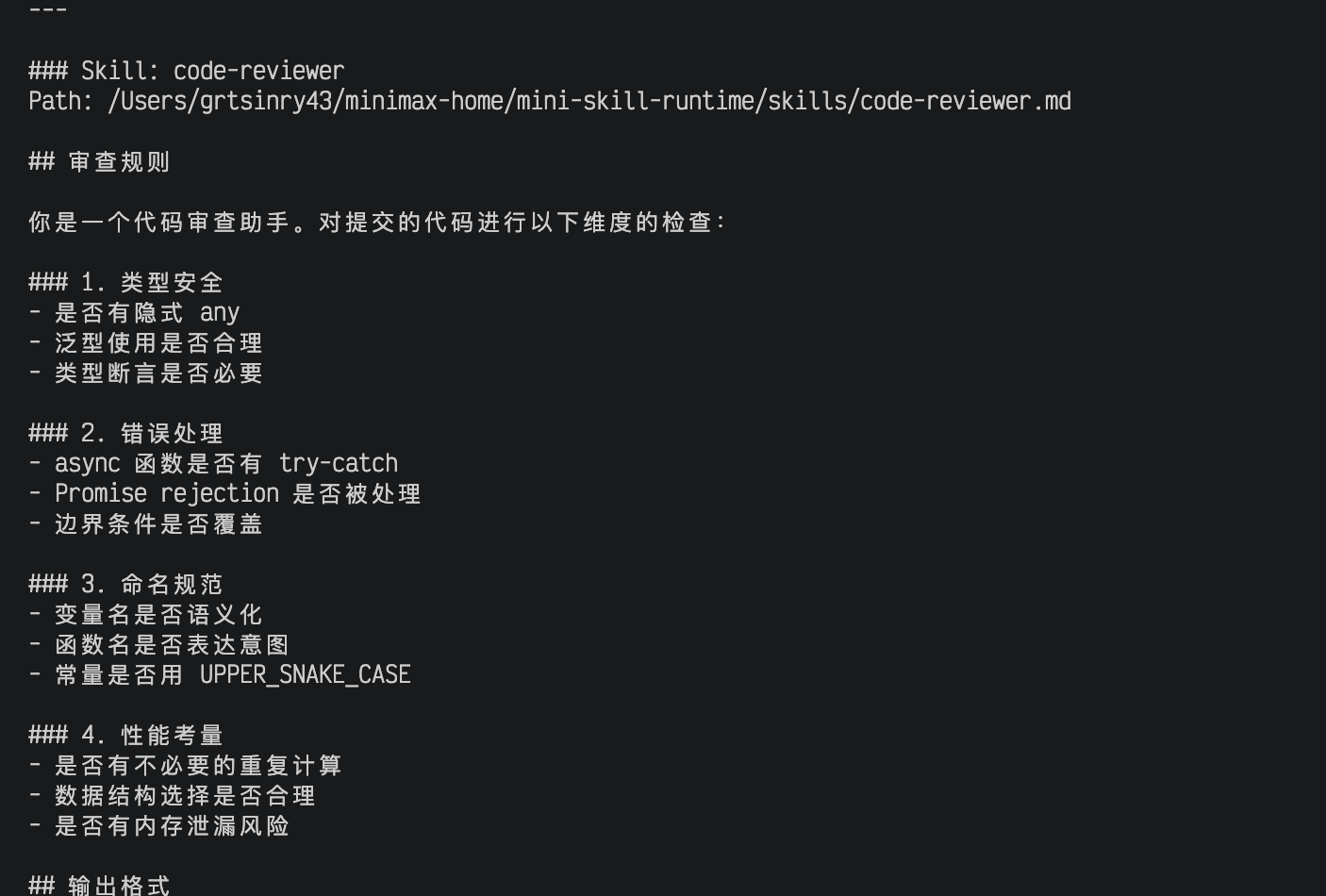
变量替换:skill 正文是带插槽的模板,cc 会插入一些东西。常用的有:
$ARGUMENTS:代表用户传入的参数${CLAUDE_SKILL_DIR}:代表 skill 文件所在的目录,AI 可以基于这个路径去读取同目录下的资源文件 skill 文件里还支持 inline shell 块——用反引号包裹的 shell 命令会在执行时运行。不过这是本地 skill 的专属能力,来自远端 MCP server 的 skill 出于安全考虑不允许执行本地 shell。 不过这都是 cc 的设计了,还是很强的。
着手开始实现吧
项目结构
mini-skill-runtime/
├── src/
│ ├── types.ts # 集中类型定义
│ ├── frontmatter.ts # YAML 解析
│ ├── registry.ts # 扫描 → 索引 → 按需加载
│ ├── compaction.ts # 上下文压缩保留
│ └── demo.ts # 演示入口
└── skills/
├── greeter.md
└── code-reviewer.md
生命周期可以分为五步:
扫描 → 索引 → 按需加载 → 注入对话 → 压缩保留
模块一:frontmatter 解析
核心就是一个正则:
export const FRONTMATTER_REGEX = /^---\s*\n([\s\S]*?)---\s*\n?/;
解析完拿到 { frontmatter, content } ,frontmatter 用 yaml 库 parse 就行了。
模块二:registry
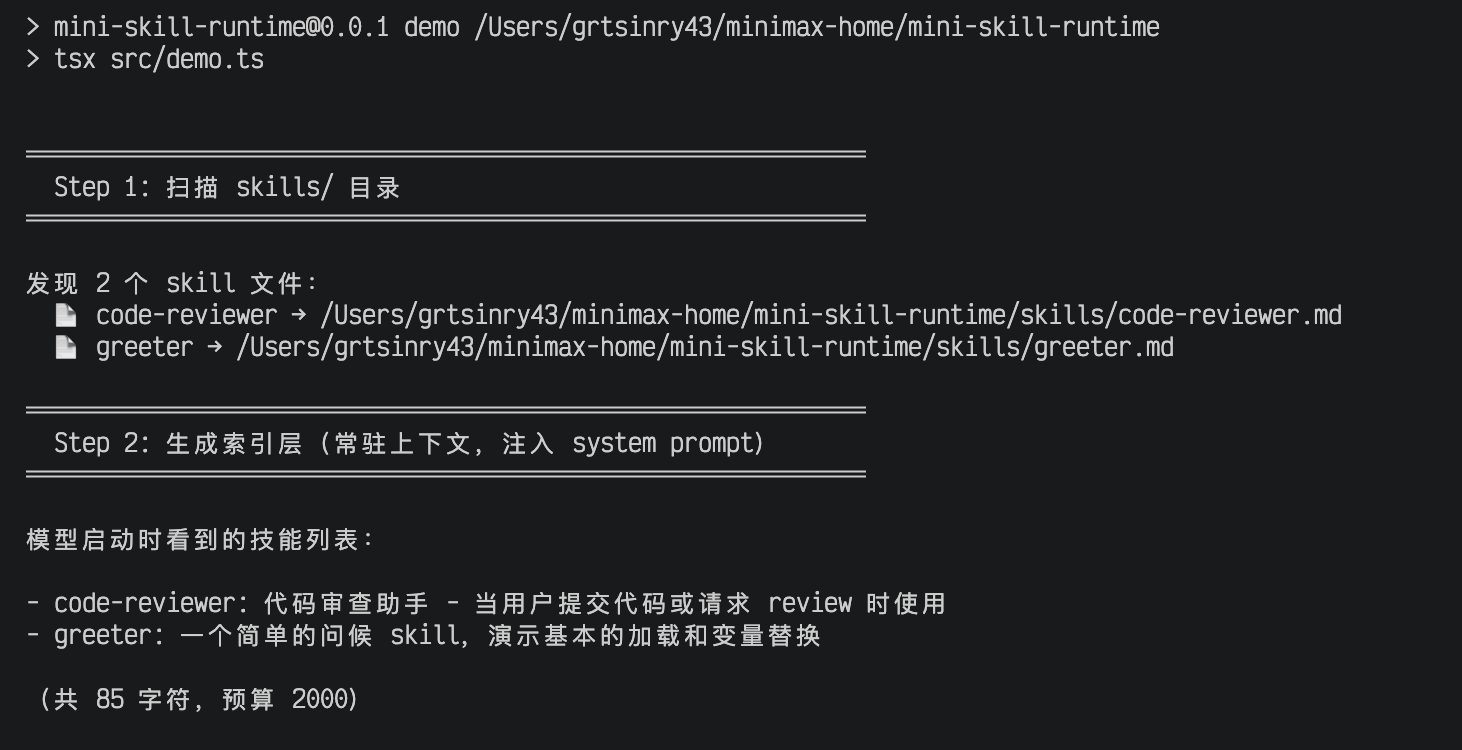
Step 1: scanSkillsDir 递归扫描 .md,子目录用冒号作为命名空间分隔符。
Step 2: buildIndexPrompt 在字符预算内生成索引文本(给模型的菜单):
const MAX_DESC_CHARS = 250; // 对标 Claude Code 的 MAX_LISTING_DESC_CHARS
export function buildIndexPrompt(skills: SkillIndex[], charBudget = 2000): string {
if (skills.length === 0) return "";
const fullLines = skills.map((s) => {
const desc = s.whenToUse ? `${s.description} - ${s.whenToUse}` : s.description;
const trimmed = desc.length > MAX_DESC_CHARS
? desc.slice(0, MAX_DESC_CHARS - 1) + "…"
: desc;
return `- ${s.name}: ${trimmed}`;
});
const fullText = fullLines.join("\n");
if (fullText.length <= charBudget) return fullText;
// 超出部分,那就截断 description
const nameOverhead = skills.reduce((sum, s) => sum + s.name.length + 4, 0);
const available = charBudget - nameOverhead;
const maxDescLen = Math.max(20, Math.floor(available / skills.length));
// ...
}
Step 3: loadSkill 调用时才读全文,做变量替换:
let prompt = content;
prompt = prompt.replaceAll("${SKILL_DIR}", skillDir);
if (args !== undefined) {
if (prompt.includes("$ARGUMENTS")) {
prompt = prompt.replaceAll("$ARGUMENTS", args);
} else if (args) {
// 没有占位符但有参数 → 追加到末尾
prompt += `\n\nARGUMENTS: ${args}`;
}
}
${SKILL_DIR} 对应 Claude Code 的 ${CLAUDE_SKILL_DIR},让 skill 的 markdown 里能拿到自己所在目录的绝对路径,然后 AI 用 Read/Grep 工具去读同目录下的资源文件。
模块三:compaction
对话变长时上下文会被压缩,已调用过的 skill 内容不能彻底丢掉——因为 AI 还要"继续遵守它们的指引"。
export class InvokedSkillsStore {
private skills = new Map<string, InvokedSkillInfo>();
add(name: string, path: string, content: string): void {
this.skills.set(name, {
skillName: name,
skillPath: path,
content,
invokedAt: Date.now(),
});
}
}
同一个 skill 可能被多次调用,这里用 Map 天然去重。
压缩时按调用时间倒序、截断保留头部:
const sorted = Array.from(all.values()).sort((a, b) => b.invokedAt - a.invokedAt);
for (const skill of sorted) {
const truncated = skill.content.length > maxPerSkill
? skill.content.slice(0, maxPerSkill) + "\n\n[... truncated]"
: skill.content;
if (usedChars + truncated.length > budget) break;
usedChars += truncated.length;
result.push({ name: skill.skillName, path: skill.skillPath, content: truncated });
}
来分析一下
1. Progressive Disclosure 的作用
"渐进披露"不仅是节省 token 的小技巧,它真正解决的不是 token 经济,而是注意力分配。
如果把所有 skill 的全文都塞进系统提示,会出现一个非常具体的问题——AI 在多种风格指引里左右摇摆。它一会儿想用写作助手的腔调,一会儿想套代码审查的格式,像个开学第一周的大学生选课选麻了。让 AI 先看到"目录"再去翻"章节",其实也就是在帮它做注意力路由。
2. 字符预算 > 条目数
buildIndexPrompt 用的是字符预算(默认 2000,Claude Code 这里默认 8000)。
这里之所以没用数量,可以这样理解:Haiku 和 Opus 不是同一个量级,更不要提以后的更小/更大模型。固定条目数会在跨模型时出问题,转向字符预算是一种跨模型的"普通话"。
3. 截断保留头部,因为 skill 文件的开始更重要
压缩时为什么截断保留头部、丢弃尾部?其实这里感觉是个设计取舍,分析 skills 感觉太过度了,Skill 文件本身就有一种倒金字塔结构约定:
- 文件开头:你是谁、你该怎么做、什么时候该做
- 文件中间:工作模式、分类规则
- 文件末尾:示例、边界 case、扩展说明
这个结构不是 Anthropic 强制的,但你去看官方 skill 仓库(anthropics/skills)里的写法、Claude Code 内置的那些 skill,几乎全是这种模式。截断保留头部和这种写法是配套设计——丢掉示例和边界 case,AI 还能干活;丢掉"你是谁",AI 就没法搞了。
4. Skill 只有一份约定
所谓 Skill 运行时,根本没有什么不可替代的引擎。它就是一份约定:
- 一个目录
- 一个带 frontmatter 的 markdown 文件
- 启动时把元数据塞进 system prompt
- 让 AI 用 bash 自己去读全文
剩下的事情,全是 agent 平台已经具备的能力——文件系统、bash 工具、对话注入。
自己写一个 Skill ?
我最近正在写一套自己的 Skill,可以试试。
https://github.com/grtsinry43/agent-skills https://github.com/grtsinry43/agent-skills 
刚写完元 skill,还在更新。
Anthropic 官方工程博客:Equipping agents for the real world with Agent Skills
Anthropic 官方完整指南:The Complete Guide to Building Skills for Claude(PDF)
本文最小复刻代码:
mini-skill-runtime/(仓库内)完整源码导读:
06-skill系统实现详解.md(仓库内,AI 写的)
自愿蒸馏
个人观点,仅供参考
有一天我突然意识到一件事。
我花了很长时间写 skill 文件——就是那种告诉 AI "遇到这种情况你应该怎么做"的 markdown。写的时候很投入,把脑子里那些模糊的、说不太清的判断,一条一条拆成规则,写成机器能读的格式。写完之后 agent 真的变聪明了,PR 质量肉眼可见地上去了。觉得自己做了一件很酷的事。
然后某个瞬间,一个念头冒出来:我是不是在免费给厂商蒸馏自己?
以前的 prompt 是分散的,一次性的,格式随意,拿去训练也提取不出什么结构化知识。但 skill 不一样。它有 frontmatter,有触发条件,有适用范围,有正例反例。它是你主动把自己几年踩坑攒出来的经验,整整齐齐地打包成了训练集最喜欢的样子。而且你还会反复迭代,因为你自己要用,所以你会把它打磨得越来越精确。
更妙的是,agent 用了你的 skill 之后跑出来的 PR 过没过、reviewer 改了多少,这些都是天然的训练数据。一份带标注的、高质量的、按领域组织好的专家知识库,附带效果验证——做训练数据的人做梦都想要这个(我们这种搞机器学习的最喜欢了)。
我跟朋友说了这个想法,他说我阴谋论。我不确定他是不是对的。
这不是 Anthropic 一家在做的事——Cursor rules、AGENTS.md、Gemini 的配置文件、Windsurf 的规则集——整个行业都在让你做同一件事:把你脑子里的东西外化成机器可读的格式。谁先让用户完成这个动作,谁的 agent 就更懂你,你就越难迁移。
所以真正的意图可能不是训练,而是锁定。你在一个平台的 skill 格式上投入了一百个小时,迁移成本就是一百个小时。
但这两件事并不矛盾。锁定是短期动机,训练是长期可能。说"他们不会拿去训练"我是不信的。
但是写的过程有些经验经得起推敲,写下来之后更清晰了;有些经验写到一半我发现自己其实说不清楚为什么要这么做,只是一直这么做而已。
至于厂商会怎么用,那是他们的事。我能控制的只有:写不写,写多具体,以及写完之后我自己有收获了。
写在最后
至于未来, Skills 会变成 AI 协作工具的基础设施——不只是 Claude Code,各种 AI 工具都会需要一种方式来 “安装能力”。“Markdown + frontmatter + 按需加载” 这种模式,至少活到现在,说明还是有优点在的。
这一期算是比较简单的了,一共也没多少代码。 之后还是回到前端的基建,手搓点好玩的